اپل با معماری Flow-Matching به تولید سریع و دقیق متن دست یافت
اپل از مدل زبانی FS-DFM رونمایی کرد؛ این مدل با تنها ۸ مرحله اصلاح، متنهایی با کیفیت بالا و سرعتی ۱۲۸ برابر سریعتر از مدلهای رایج تولید میکند.

اپل در همکاری با دانشگاه ایالتی اوهایو از مدل زبانی جدیدی با نام Few-Step Discrete Flow-Matching یا FS-DFM رونمایی کرد که قادر است متنهای بلند را با سرعتی خارقالعاده تولید کند. طبق گزارش 9to5Mac، این مدل میتواند با تنها ۸ مرحله اصلاح، متنی با کیفیت برابر با مدلهای دیفیوژن رایج که به بیش از ۱۰۰۰ مرحله نیاز دارند تولید کند.
تفاوت معماری FS-DFM با مدلهای رایج
مدلهای زبانی رایج مانند چتجیپیتی از نوع خودبازگشتی (Autoregressive) هستند؛ یعنی متن را بهصورت ترتیبی و توکنبهتوکن تولید میکنند. در مقابل، مدلهای دیفیوژن (Diffusion) چندین توکن را بهصورت موازی تولید کرده و طی مراحل اصلاحی به نتیجه نهایی میرسند. FS-DFM از نوع Flow-Matching است که فرآیند اصلاح را بهصورت مستقیم و بدون تکرار انجام میدهد.


در مقالهای با عنوان FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models، محققان اپل توضیح دادهاند که این مدل با استفاده از سه مرحله کلیدی توسعه یافته است:
- آموزش مدل برای مدیریت تعداد مختلف مراحل اصلاح
- استفاده از مدل راهنما (Teacher Model) برای هدایت اصلاحات دقیقتر
- بهینهسازی الگوریتم اصلاح برای رسیدن به نتیجه نهایی در کمترین زمان

عملکرد و مقایسه با مدلهای بزرگ
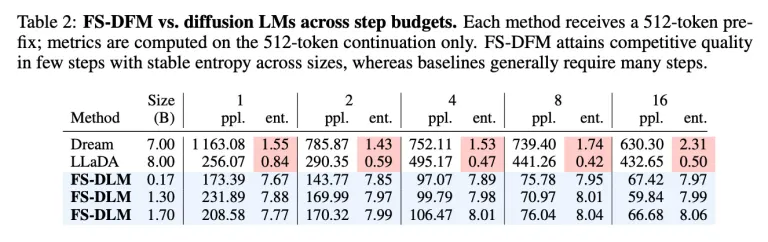
در آزمایشهای انجامشده، FS-DFM با نسخههایی با ۱.۷، ۱.۳ و ۰.۱۷ میلیارد پارامتر، توانسته نمره پرپلکسی (Perplexity) پایینتر و ثبات در آنتروپی (Entropy) بیشتری نسبت به مدلهای Dream (۷ میلیارد پارامتر) و LLaDA (۸ میلیارد پارامتر) کسب کند. پرپلکسی پایین نشاندهنده طبیعی بودن متن تولیدشده است و آنتروپی متعادل از تکرار یا تصادفی بودن بیش از حد جلوگیری میکند.
محققان اپل اعلام کردهاند که قصد دارند کد منبع و نقاط بررسی مدل را منتشر کنند تا امکان بازتولید و تحقیقات بیشتر فراهم شود. نسخه کامل مقاله در arXiv منتشر شده است.
لینکهای بیشتر:



